
Activity 2: Audio Recognition
Train and Test the Audio Classifier


The first step is to open Google Teachable Machine in order to create an audio recognition model.
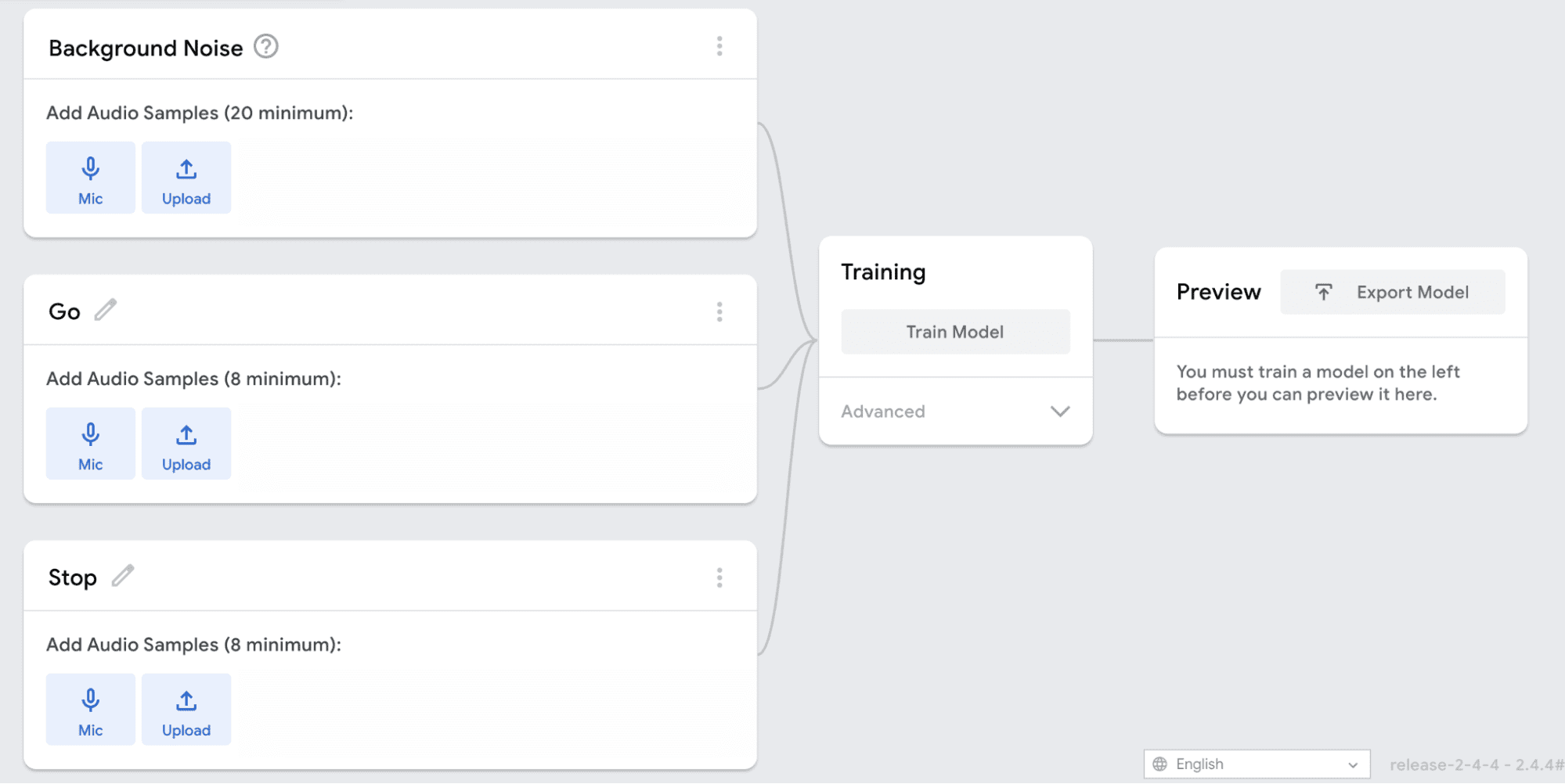
You will need to be in a quiet room for this. Decide how many classes you want and name them. Each category should be a single word. For an audio model, the first category must always be “Background Noise.” The example shown here was trained with background noise, the word “go,” and the word “stop.”
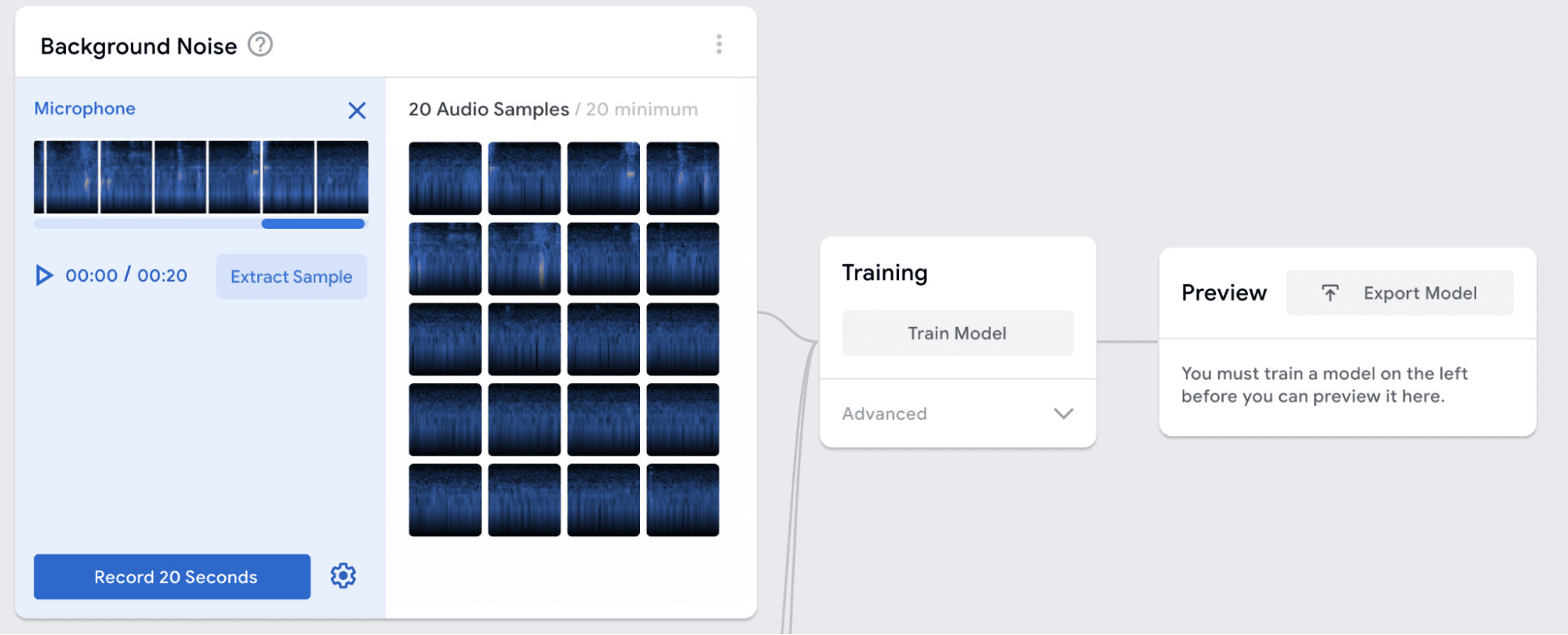
Use the microphone button to record 20 seconds of background noise. Make sure that the room is quiet while you record these samples. Then click the Extract Sample button. The screen should show 20 audio samples.

Next you will add samples for each of your classes. First, click on the settings button.
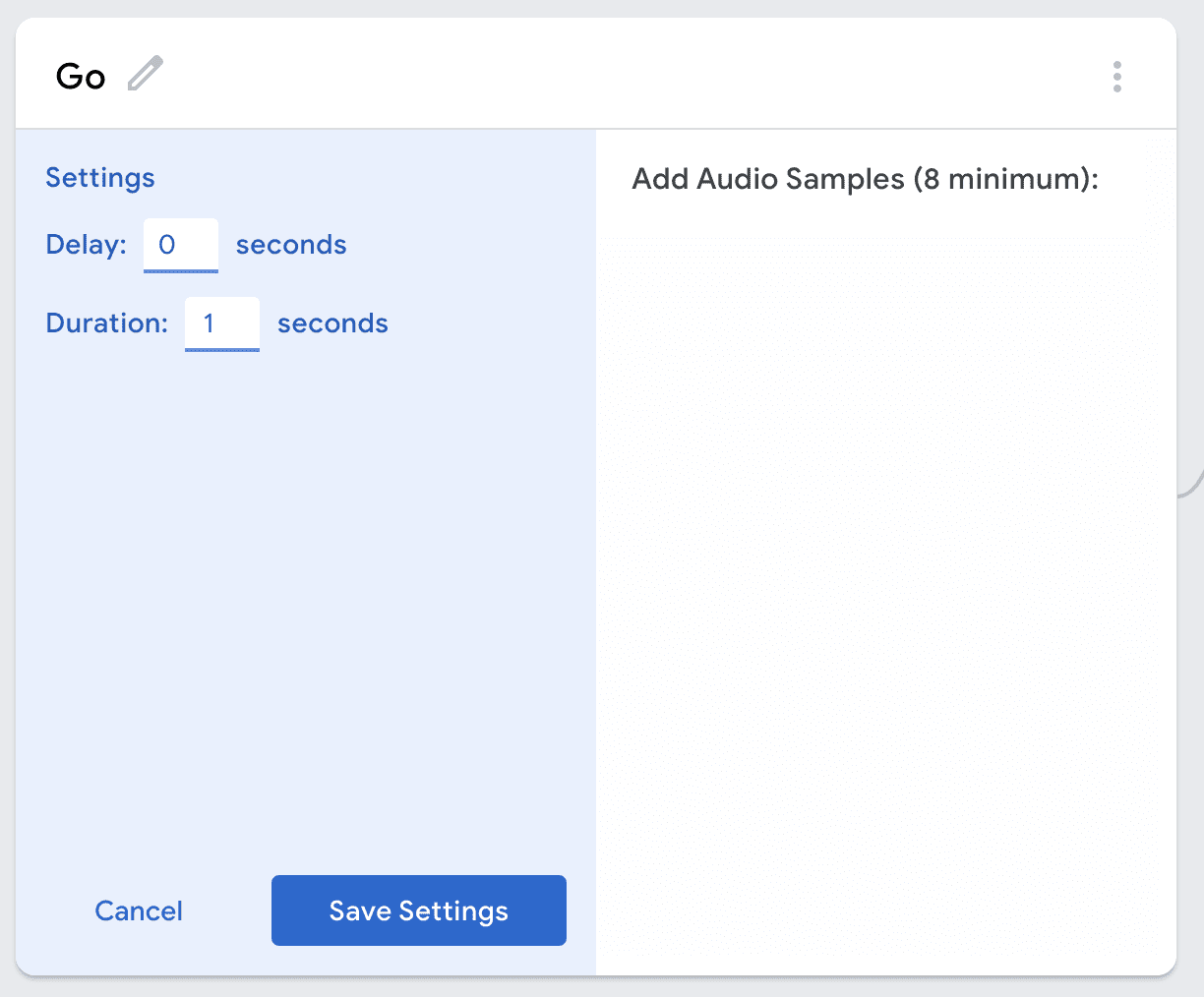
Change the duration to 1 second and then click Save Settings. Make sure you do this for all of your classes.

For each class, record yourself saying the chosen word at least eight times. After recording each file, you can use the play button to hear it. If the word was recorded clearly, click Extract Sample.
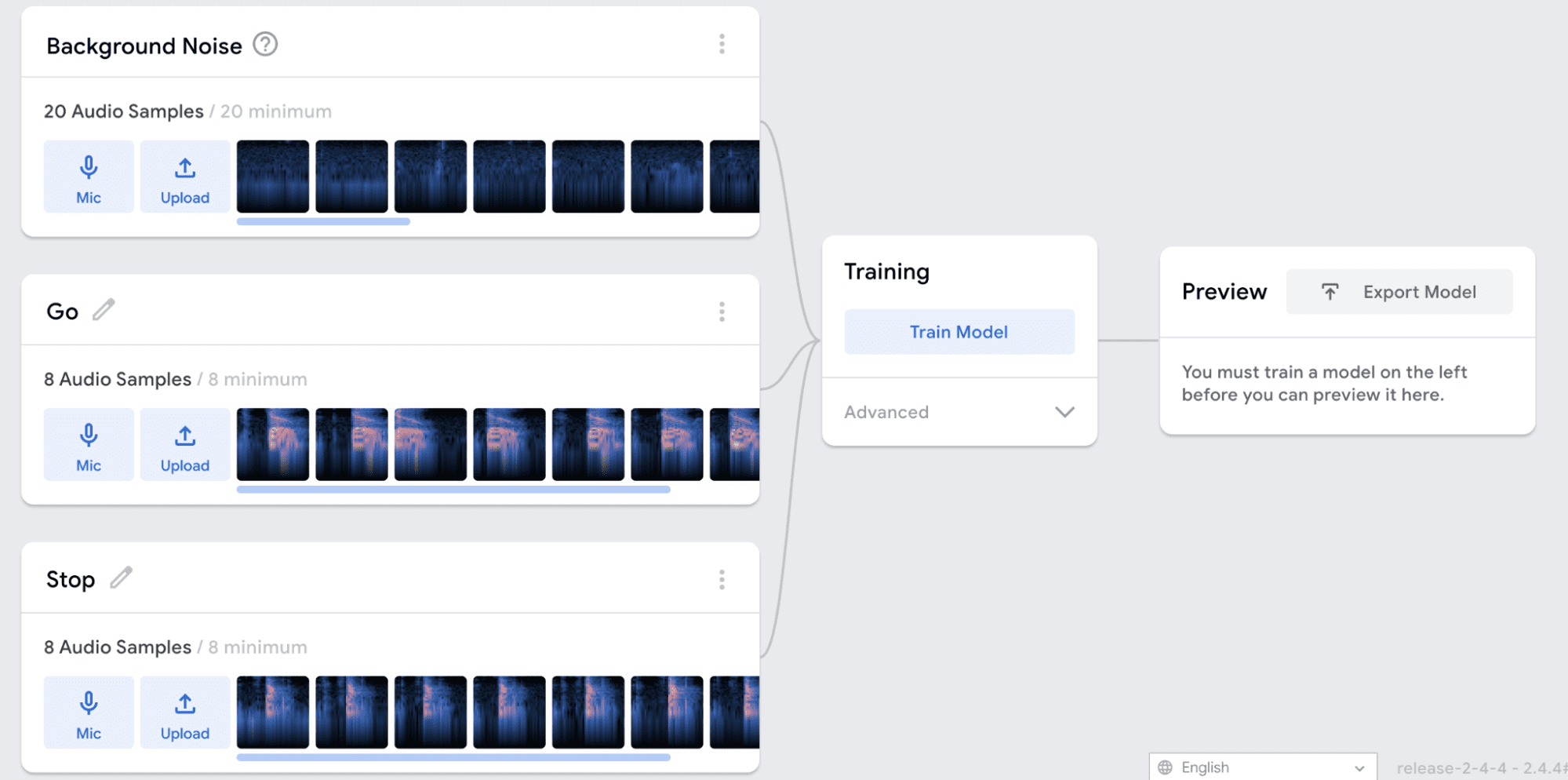
When you have finished recording data, you should have at least twenty samples of background noise and at least eight samples for each of the other classes. Once you have collected enough data, click Train Model.
The training will take about a minute. Make sure to leave the tab open while the model is training, even if your browser pops up a warning that the window is unresponsive.
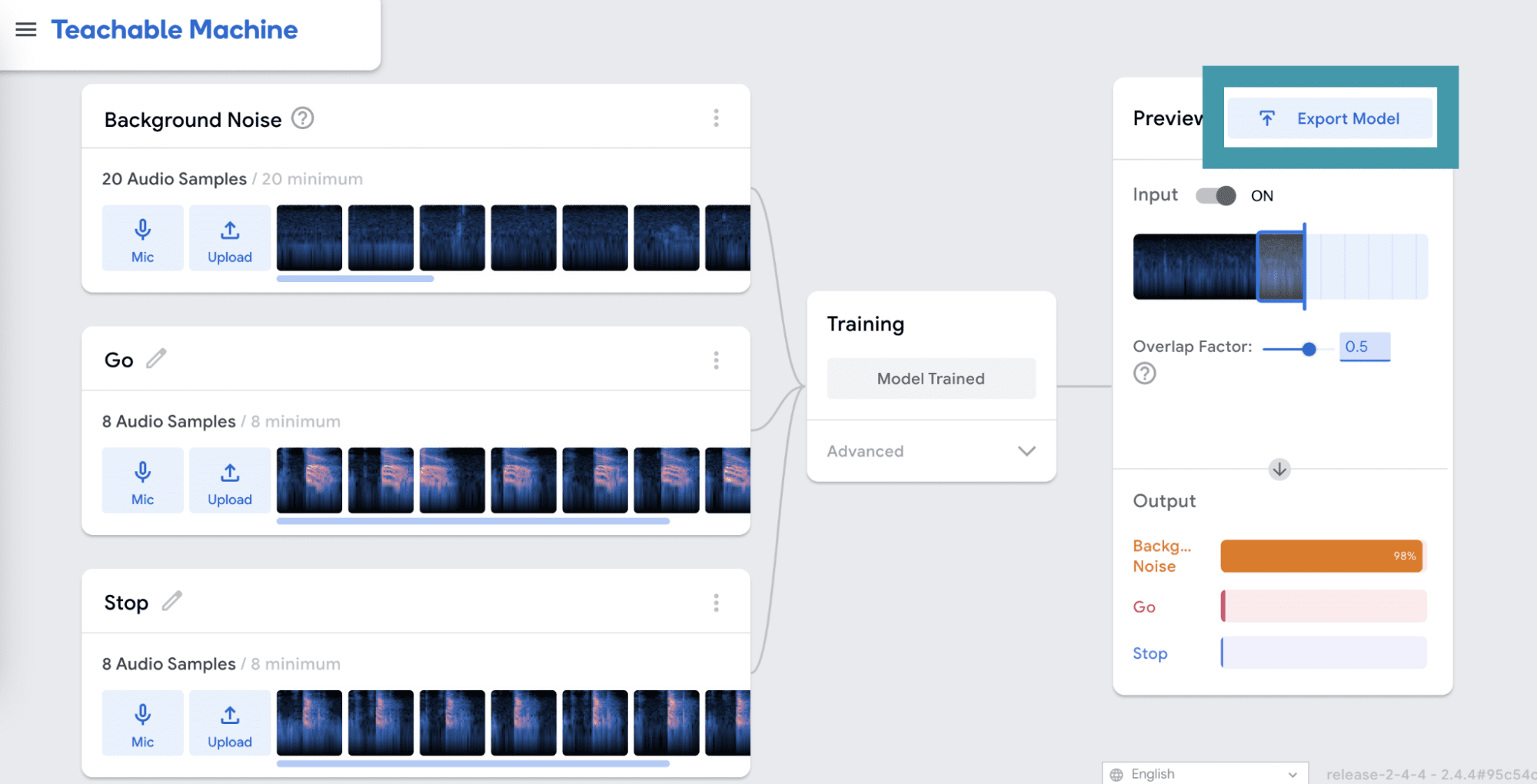
When the training is complete, you will be able to test your model in the Preview panel. Make sure that your model works the way that you want it to before moving on. If it doesn’t, you may need to add more audio samples for each class and train again. When you are happy with your model, click Export Model.
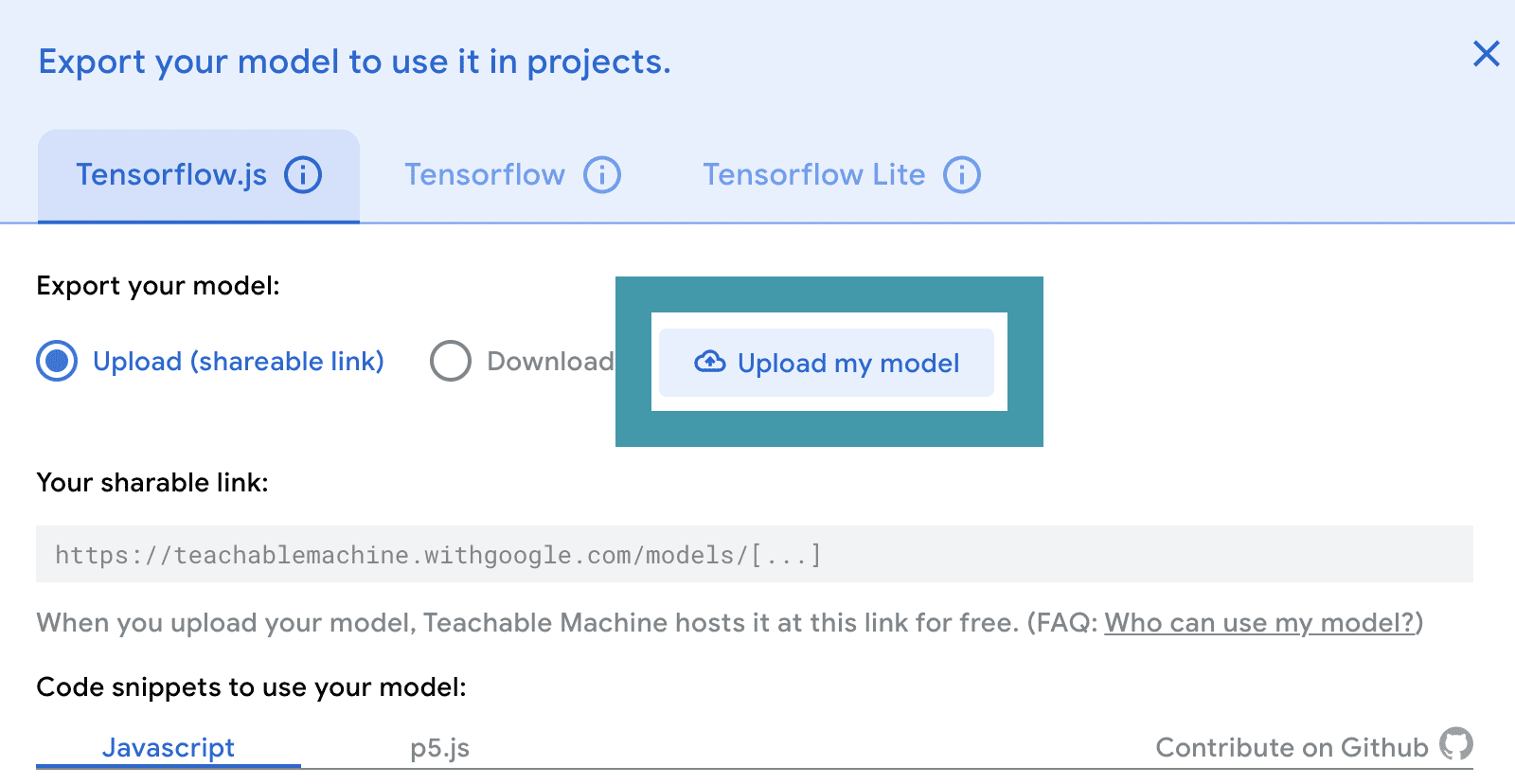
Keep all of the defaults as they are, and click Upload my model. After your model has uploaded, copy your sharable link. You will need this link to create a Python program with your model. After you copy the link, you can close the export window.
Remember to save your model in case you want to reference or change it later. Click on the Teachable Machine menu and either download the file or save it to your Google drive.
Using the Audio Classifier in Python
Open brython.birdbraintechnologies.com and connect to the Finch. You should use the browser-based version of Python for this activity because it already has all of the machine learning methods that you will need.

First, load the machine learning model into Python. Then use MachineLearningModel.load() to import your audio recognition model. This is very similar to what you did for image recognition, except that the second parameter of MachineLearningModel.load() should be “audio.”

Once you have loaded the model, you can use MachineLearningModel.getPrediction() to get the results of your machine learning model for the current sound detected by the microphone. Print these results to the screen and run your program. Remember, it can take up to a minute for the classification to start the first time you run the script.

As you learned in image recognition, MachineLearningModel.getPrediction() returns a dictionary. Each class label is a key for the dictionary, and the value that corresponds to that key is the probability that the current sound belongs to that class.
You can use the values returned by MachineLearningModel.getPrediction() to make the Finch perform certain actions when each class is detected. For example, this code starts the Finch wheels when it detects the word “go,” and stops them when it hears the word “stop.”
Challenge: Write a program to make the Finch respond to each of your words. As you test your program, notice what happens if you say a word that your model does not know. What happens if a different voice says the trained words?